一、LightGCN [2020]
《LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation》
为减轻网上的信息过载,推荐系统已被广泛部署以执行个性化的信息过滤。推荐系统的核心是预测用户是否会和
item进行交互,例如点击、评论、购买、以及其它形式的交互。因此,协同过滤(collaborative filtering: CF)仍然是用于个性化推荐的基础(fundamental)任务。其中,CF专注于利用历史user-item交互来实现预测。CF最常见的范式是学习潜在特征(也称为embedding)来表示用户和item,并基于embedding向量进行预测。矩阵分解是一种早期的此类模型,它直接将
user ID直接映射到user embedding。后来一些研究发现,利用用户的历史交互作为输入来增强(
augmenting)user ID可以提高embedding的质量。例如:SVD++展示了用户历史交互在预测用户评分方面的好处。Neural Attentive Item Similarity: NAIS区分了历史交互中item的重要性,并显示了在预测item ranking方面的改进。
从
user-item交互图(interaction graph)来看,这些改进可以视为来自于用户子图结构(user subgraph structure)(更具体而言,这子图结构就是用户的直接邻居)来改进embedding learning。为了深化高阶邻居子图结构的使用,人们提出了
NGCF从而为CF实现了SOTA的性能。NGCF从图卷积网络(Graph Convolution Network: GCN)中汲取灵感,遵循相同的传播(propagation)规则来refine embedding:特征变换(feature transformation)、邻域聚合(neighborhood aggregation)、非线性激活(nonlinear activation)。
尽管
NGCF已经显示出有希望的结果,但是LightGCN的作者认为NGCF的设计相当沉重(heavy)和冗余(burdensome):很多操作毫无理由地直接从GCN继承下来(而并没有对GCN进行彻底的理论研究和消融分析)。因此,这些操作不一定对CF任务有用。具体而言,GCN最初是针对属性图(attributed graph)上的节点分类(node classification)任务提出的,其中每个节点都有丰富的属性作为输入特征。而在CF的user-item交互图中,每个节点(user或者item)仅由一个one-hot ID来描述,除了作为标识符之外没有任何具体的语义。在这种情况下,给定ID embedding作为输入,执行多层非线性特征变换(这是现代神经网络成功的关键)不会带来任何好处,反而会增加模型训练的难度。为了验证这一想法(即
NGCF中的这些操作不一定对CF任务有用),在论文《LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation》中,作者对NGCF进行了广泛的消融研究。通过严格的控制实验(在相同的数据集拆分和评估协议上),作者得出结论:从GCN继承的两个操作,特征转换和非线性激活,对NGCF的有效性(effectiveness)没有贡献。更令人惊讶的是,删除这两个操作会显著提高准确性(accuracy)。这反映了在图神经网络中添加对目标任务无用(useless)操作的问题:不仅没有带来任何好处,反而降低了模型的有效性。受到这些经验发现的启发,作者提出了一个名为
LightGCN的新模型,其中仅包括GCN最重要的组件(component)用于协同过滤 ,即:邻域聚合。具体而言:在将每个用户(
item)和ID embedding关联之后,模型在user-item交互图上传播embedding来refine这些embedding。然后,模型将不同传播层(
propagation layer)学习的embedding以加权和的方式聚合,从而获得用于预测的最终embedding。
整个模型简单而优雅,不仅更容易训练,而且比
NGCF和其它SOTA方法(如Mult-VAE)获得了更好的实验性能。总而言之,论文的主要贡献如下:
经验表明:
GCN两种常见设计,特征变换和非线性激活,对协同过滤的有效性没有正面影响。论文提出了
LightGCN,它通过仅包含GCN中最重要的组件进行推荐,从而在很大程度上简化了模型设计。论文通过遵循相同的实验
setting,在实验中对比了LightGCN和NGCF,并展示了实质性的提升。论文还从技术和经验两个角度对
LightGCN的合理性进行了深入分析。
相关工作:
协同过滤:协同过滤(
Collaborative Filtering: CF)是现代推荐系统中的一种流行技术。CF模型的一种常见范式是将用户和item参数化为embedding,并通过重建历史user-item交互来学习embedding参数。早期的CF模型,如矩阵分解(matrix factorization: MF)将用户(或item)的ID映射到embedding向量中。最近的神经推荐模型如NCF和LRML使用相同的embedding组件,但是同时增强了基于神经网络的交互建模(interaction modeling)。除了仅使用
ID信息之外,另一种类型的CF方法将历史item视为用户已经存在(pre-existing)的特征,从而实现更好的user representation。例如,FISM和SVD++使用历史item的ID embedding的加权均值作为目标用户的embedding。最近,研究人员意识到历史item对塑造个人兴趣有不同的贡献。为此,人们引入了注意力机制来捕获不同的贡献,如ACF和NAIS,从而自动学习每个历史item的重要性。当以user-item二部图的形式重新审视历史交互时,性能的提高可以归因于局部邻域(一阶邻域)的编码,这可以改进embedding learning。即,将历史
item视为用户行为特征,这是一种二部图上的局部邻域编码技术。用于推荐的图方法:另一个相关的研究方向是利用
user-item图结构进行推荐。之前的工作,如
ItemRank,使用标签传播机制(label propagation mechanism)在图上直接传播用户偏好分(user preference score),即鼓励相连的节点具有相似的label。最近出现的图神经网络(graph neural network: GNN)揭示了图结构建模,尤其是高阶邻居,从而指导embedding learning。早期的研究定义了谱域(
spectral domain)上的图卷积,例如拉普拉斯特征分解(Laplacian eigen-decomposition)(《Spectral Networks and Locally Connected Networks on Graphs 》)和切比雪夫多项式(Chebyshev polynomial)(《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》),但是它们的计算成本很高。后来,
GraphSage和GCN重新定义了空域(spatial domain)中的图卷积,即聚合邻域的embedding从而refine目标节点的embedding。由于其可解释性(interpretability) 和效率(efficiency),它们很快成为GNN的流行公式并被广泛使用。受图卷积力量的推动,
NGCF、GC-MC、PinSage等最近的努力使得GCN适应于user-item交互图,并捕获高阶邻域中的CF信号从而进行推荐。
值得一提的是,最近的一些努力提供了对
GNN的深入洞察(insight),这激发了我们开发LightGCN。具体而言,《Simplifying Graph Convolutional Networks》认为GCN不必要的复杂性,通过移除非线性、并将多个权重矩阵融合为一个从而开发简化的GCN(simplified GCN: SGCN)模型。LightGCN和SGCN的一个主要区别是:它们是针对不同的任务开发的,因此模型简化的合理性是不同的。具体而言:SGCN用于节点分类,对模型的可解释性和效率进行了简化。相比之下,
LightGCN用于协同过滤,其中每个节点只有一个ID特征。因此,我们执行简化的理由更充分:非线性和权重矩阵对于CF毫无用处,甚至会损害模型训练。
对于节点分类准确性,
SGCN与GCN相当(有时弱于)。对于CF准确性,LightGCN的性能大大优于GCN(比NGCF提高了15%以上)。最后,同时进行的另一项工作
《Revisiting Graph based Collaborative Filtering: A Linear Residual Graph Convolutional Network Approach》也发现非线性在NGCF中是不必要的,并为CF开发了线性GCN模型。相比之下,我们的LightGCN更进了一步:我们删除了所有冗余参数,仅保留了ID embedding,使模型像MF一样简单。
1.1 模型
1.1.1 NGCF
我们首先介绍
NGCF,这是一个具有代表性的、SOTA的GCN推荐模型。然后我们对NGCF进行消融研究,以判断NGCF中每个操作的有效性。本节的贡献是表明GCN中的两种常见操作,特征转换和非线性激活,对协同过滤没有正面影响。
a. NGCF 介绍
首先每个用户和每个
item都关联一个ID embedding。令ID embedding、itemID embedding。NGCF利用user-item交互图来传播embedding,即:其中:
itemrefined embedding。item集合,itemuser集合。
通过传播
NGCF得到了embeddingembeddingitem。然后
NGCF拼接这embedding从而获得最终的user embedding和item embedding,并使用内积来生成预估分。NGCF很大程度上遵循了标准的GCN,包括使用非线性激活函数在半监督节点分类任务中,每个节点都有丰富的语义特征作为输入,例如一篇文章的标题和关键词。因此,执行多层非线性变换有利于特征学习。
然而在协同过滤中,
user-item交互图的每个节点只有一个id作为输入,没有具体的语义。在这种情况下,执行多层非线性变换无助于学习更好的特征。更糟糕的是,执行多层非线性可能会增加训练的难度。接下来我们将提供实验的证据。
b. NGCF 实验探索
我们对
NGCF进行消融研究,从而探索非线性激活和特征变换的影响。我们使用NGCF作者发布的代码,在相同的数据集拆分和评估协议上运行实验,以保持尽可能公平地比较。由于
GCN的核心是通过传播来refine embedding,因此我们对相同embedding size下的embedding质量更感兴趣。因此,我们将获得最终embedding的方式从拼接(即NGCF的性能影响不大,但是使得以下消融研究更能够表明GCN的refined embedding质量。我们实现了
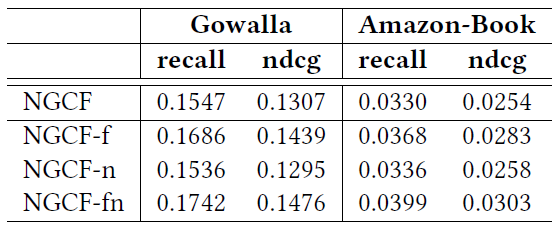
NGCF的三个简化的变体:NGCF-f:删除特征变换矩阵NGCF-n:删除非线性激活函数NGCF-fn:同时删除特征变换矩阵和非线性激活函数。
对于这三个变体,我们保持所有超参数(例如学习率、正则化系数、
dropout rate等等)和NGCF的最佳配置相同。我们在下表中报告了
Gowalla和Amazon-Book数据集上2-layer setting的结果。可以看到:删除特征变换(即
NGCF-f)导致在所有三个数据集上对NGCF的持续提升。相比之下,删除非线性激活函数(即
NGCF-n)不会对准确性accuracy产生太大影响。如果我们同时删除特征变换矩阵和非线性激活函数(即
NGCF-fn),那么性能会得到显著提高。
根据这些观察,我们得出以下结论:
添加特征变换对
NGCF产生负面影响,因为在NGCF和NGCF-n这两个模型中删除特征变换(即NGCF-f和NGCF-fn)显著提高了性能。添加非线性激活函数在包含特征变换时影响很小(
NGCF vs NGCF-n),但是在禁用特征变换时会产生负面影响(NGCF-f vs NGCF-fn)。总体而言,特征变换和非线性激活函数对
NGCF产生了相当负面的影响。因为通过同时移除它们,NGCF-fn表现出比NGCF的巨大提升(召回率相对提高9.57%)。
为了更深入地了解表中获得的分数,以及理解为什么
NGCF在这两种操作下(特征变换和非线性激活)恶化,我们在下图中绘制了训练损失和测试recall。可以看到:
在整个训练过程中,
NGCF-fn的训练损失要比NGCF, NGCF-f, NGCF-n低得多。NGCF-fn的训练损失和测试的recall曲线保持一致,并且这种较低的训练损失成功地转化为更好的推荐准确性。NGCF和NGCF-f之间的比较显式了类似的趋势,只是提升幅度较小。
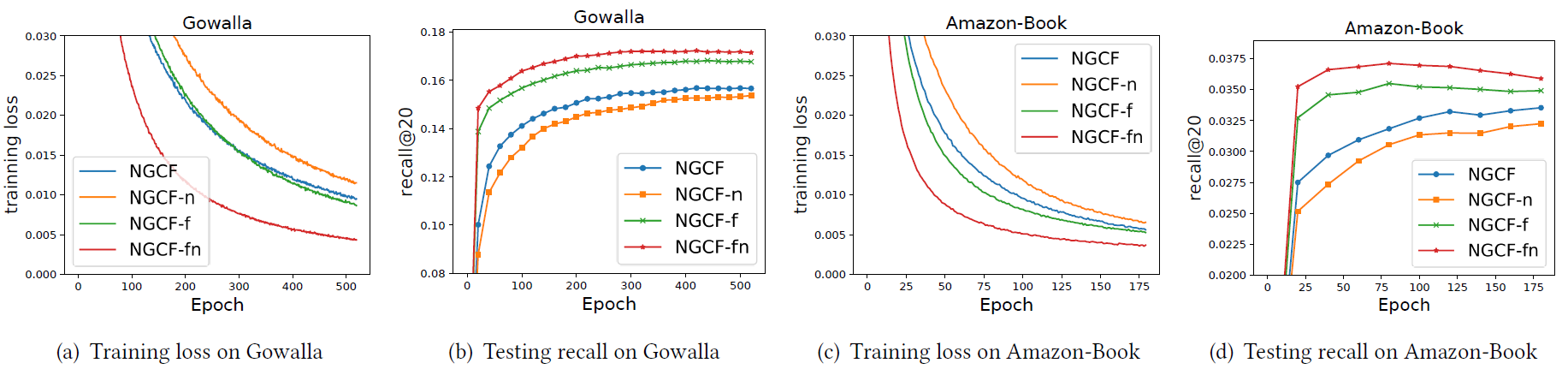
从上述证据中我们可以得出结论:
NGCF的性能恶化源于训练难度,而不是过拟合。从理论上讲,
NGCF比NGCF-f具有更强的表示能力,因为将权重矩阵NGCF-f模型。然而在实践中,NGCF表现出比NGCF-f更高的训练损失和更差的泛化性能。非线性激活的加入进一步加剧了表示能力和泛化性能之间的差异。NGCF相比NGCF-f更高的训练损失,这就是训练难度的表现。理论上NGCF的模型容量更大,那么训练损失应该更低。假如NGCF模型的训练损失更低、但是测试auc反而更差,那么就是过拟合的表现。为了完善这一部分内容,我们主张在设计推荐模型时,进行严格的消融研究以明确每个操作的影响是非常重要的。否则,包含不太有用的操作会使得模型不必要地复杂化、增加模型训练难度、甚至降低模型的有效性。
1.1.2 LightGCN
前述分析表明:
NGCF是一种用于协同过滤的沉重的、冗余的GCN模型。在这些发现的推动下,我们设定了一个目标,即通过包含GCN最基本的组件进行推荐从而开发一个轻量(light)而有效(effective)的模型。简单的模型具有以下优势:更容易解释、更容易训练和维护、技术上更容易分析模型行为并将其修改为更有效的方向,等等。在这一部分,我们首先展示我们设计的
Light Graph Convolution Network: LightGCN模型,如下图所示。在LightGCN中,仅对前一层邻居的embedding执行归一化求和(normalized sum) 。所有其它操作,如自连接(self-connection)、特征转换、非线性激活等等,都被删除。这在很大程度上简化了GCN。在Layer Combination中,我们对每一层的embedding求和以获得最终representation。然后我们对
LightGCN进行深入分析,以展示其简单设计背后的合理性。最后我们描述了如何针对推荐来进行模型训练。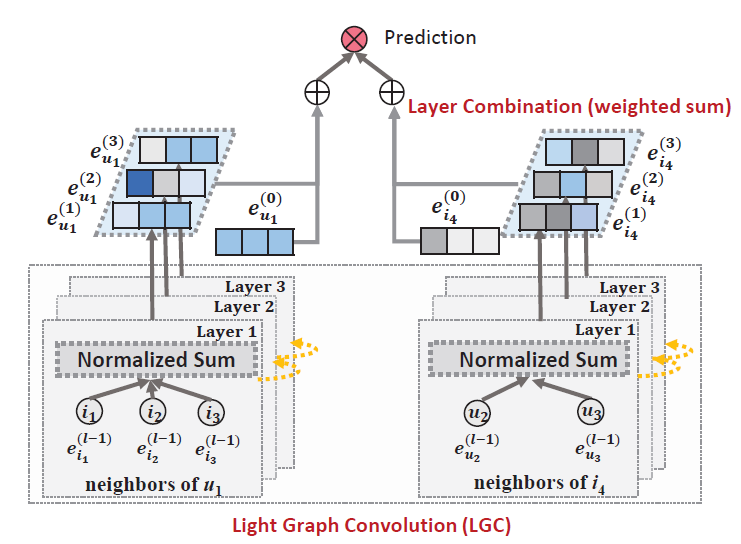
a. LightGCN
GCN的基本思想是通过在图上平滑特征来学习节点的representation。为了实现这一点,它迭代式地执行图卷积(graph convolution),即将邻居的特征聚合为目标节点的新representation。这种邻域聚合可以抽象为:其中
representation。很多工作都提出了
GIN中的weighted sum聚合器、GraphSAGE中的LSTM聚合器、BGNN中的bilinear interaction聚合器等等。然而,大多数工作都将特征转换或非线性激活与graph classification)任务上表现良好,但是它们可能对协同过滤造成负担(参考前面的初步分析结果)。Light Graph Convolution: LGC:在LightGCN中,我们采用简单的加权和聚合器,删除了特征变换和非线性激活。LightGCN中的图卷积操作定义为:对称的归一化项
GCN的设计,这样可以避免embedding的幅度(即向量的幅长)随着图卷积运算而增加。这里也可以应用其它选择,如值得注意的是:在
LGC中,我们只聚合相连的邻居,没有聚合目标节点本身(即自连接)。这和大多数现有的图卷积操作不同,现有的图卷积通常聚合扩展的邻域(包含节点自身)并需要专门处理自连接。这是因为:层组合操作(layer combination operation)本质上捕获了和自连接相同的效果,因此在LGC中没有必要包含自连接。关于层组合操作的内容接下来介绍,并且我们还将证明层组合操作和自连接本质上是相同的效果。
层组合和模型预测(
Layer Combination and Model Prediction):在LightGCN中,唯一可训练的模型参数是第0层的embedding,即所有用户的item的embedding时,可以通过LGC计算更高层的embedding。在
LGC之后,我们进一步结合在每一层获得的embedding,从而得到最终的user representation和最终的item representation:其中
embedding在构成final embedding中的重要性。它可以被视为要手动调优的超参数,也可以被视为要自动优化的模型参数。在我们的实验中,我们发现将LightGCN并保持其简单性。和
NGCF采用多层embedding的拼接聚合不同,LightGCN采用多层embedding的加权和聚合。我们执行层组合(
layer combination)从而获得final representation的原因有三个:随着层数的增加,
embedding会过度平滑(over-smooth)。因此,简单地使用最后一层是有问题的。不同层的
embedding捕获不同的语义。例如,第一层对有交互的用户和item强制执行平滑,第二层平滑与交互item(用户)重叠的用户(item),更高层捕获更高阶的邻近性(proximity)。因此,将它们组合起来将使得representation更加全面。将不同层的
embedding以加权和的方式组合,可以捕捉到带自连接的图卷积的效果,这是GCN中的一个重要技巧。
模型预测被定义
user final representation和item final representation的内积:矩阵形式:我们提供了
LightGCN的矩阵形式,以便于实现以及和现有模型的讨论。假设
user-item交互矩阵为item数量。如果用户itemuser-item交互图的邻接矩阵为:令第
0层的embedding矩阵为embedding size。则我们可以得到LGC的矩阵等价形式为:其中
最后,我们得到用于模型预测的
final embedding矩阵为:.
b. 模型分析
我们进行模型分析以证明
LightGCN简单设计背后的合理性。首先我们讨论了与
Simplified GCN的联系,这是最近的一个线性GCN模型,它将自连接集成到图卷积中。这个分析表明通过层组合,LightGCN包含了自连接的效果。因此,LightGCN不需要在邻接矩阵中加入自连接。然后我们讨论和
Approximate Personalized Propagation of Neural Predictions: APPNP的联系,这是最近的一个GCN变体,它通过从Personalized PageRank的启发来解决过度平滑问题。这个分析表明了LightGCN和APPNP之间的潜在等效性。因此,我们的LightGCN在具有可控过度平滑(controllable oversmoothing)的长距离传播方面享受同样的好处。最后,我们分析了第二层
LGC,以展示它如何平滑用户及其二阶邻居。这为LightGCN的工作机制提供更多的洞察(insights)。与
SGCN的关联:在论文《Simplifying Graph Convolutional Networks》中,作者论证了GCN对节点分类的不必要的复杂性,并提出了SGCN。SGCN通过删除非线性并将权重矩阵压缩为一个权重矩阵来简化GCN。SGCN中的图卷积定义为:其中
在下面的分析中,为简单起见,我们省略了
embedding执行缩放re-scale。在
SGCN中,最后一层得到的embedding用于下游预测任务,可以表示为:其中
上述推导表明:将自连接插入到
embedding,本质上等效于在每个LGC层传播的embedding的加权和。添加自连接相当于将每一层的
embedding向更高层传播,此时最后一层embedding隐含了各层的embedding信息。这相当于不带自连接的、LGC的各层embedding的直接聚合。和
APPNP的关联:在最近的一项工作《Predict then propagate: Graph neural networks meet personalized pagerank》中,作者将GCN和Personalized PageRank联系起来,从中得到启发,并提出一个叫做APPNP的GCN变体。该变体可以在没有过度平滑(oversmoothing)风险的情况下进行长距离传播。受到
Personalized PageRank中的传送设计(teleport design)的启发,APPNP用起始特征(starting feature)(即第0层embedding)补充每个传播层,这可以平衡(balance)保留局部性(locality)(即靠近根节点以减轻过度平滑)和利用大的邻域的信息的需要。APPNP中的传播层定义为:其中
teleport probability,在
APPNP中,最后一层用于最终预测,即:我们可以看到:通过相应的设置
LightGCN可以完全恢复APPNP使用的预测embedding。因此,LightGCN在对抗过度平滑方面具有APPNP的优势:通过适当地设置controllable oversmoothing)的长程(long-range)建模。另一个细微的区别是:
APPNP在邻接矩阵中添加了自连接。然而,正如我们之前所展示的,由于LightGCN采用了不同层embedding的加权和,因此自连接是冗余的。二阶
embedding的平滑性:由于LightGCN的线性和简单性,我们可以深入了解它如何平滑embedding。这里我们分析一个两层LightGCN来证明其合理性。以用户侧为例,直观地,第二层平滑了在交互
item上有重叠 (overlap) 的所有用户。具体而言,我们有:可以看到,如果另一个用户
item,那么smoothness strength)由以下系数来衡量:如果
item,那么该系数为零。这个系数相当容易解释:二阶邻居
共同交互
item的数量(即:共同交互
item的流行度(popularity)(即:用户
这种可解释性很好地满足了
CF在度量用户相似性时的假设,并证明了LightGCN的合理性。由于
LightGCN公式的对称性,我们可以在item方面得到类似的分析。LightGCN和SGCN的一个主要区别在于:LightGCN和SGCN是针对不同的任务开发的,因此模型简化的合理性是不同的。具体而言:SGCN用于节点分类,对模型的可解释性和效率进行简化。相比之下,LightGCN用于协同过滤CF,其中每个节点只有一个ID特征。因此我们做简化的理由更充分:非线性和权重矩阵对于协同过滤毫无用处,甚至会损害模型训练。
c. 模型训练
LightGCN的可训练参数只是第0层的embedding,即matrix factorization: MF)相同。我们采用贝叶斯个性化排序(
Bayesian Personalized Ranking)损失函数。BPR loss是一种pairwise loss,它 鼓励观察到的item的预测高于未观察到的对应item:其中
我们采用
Adam优化器,并以mini-batch的方式优化。我们知道其它可能会改进
LightGCN训练的高级负采样策略,如hard负采样和对抗采样(adversarial sampling)。我们把这个扩展放在未来,因为它不是这项工作的重点。
注意,我们没有引入
GCN和NGCF中常用的dropout机制。原因是我们在LightGCN中没有特征变换权重矩阵,因此在embedding层上执行LightGCN简单性的优点:比NGCF更容易训练和调优。NGCF需要额外地调优两个dropout rate(node dropout和message dropout),并将每层的embedding归一化为单位长度。还可以学习层的组合系数
活跃用户具有大量的一阶
item邻居,因此使用低阶邻居就可以得到良好的用户representation;稀疏用户具有很少的一阶item邻居,因此需要高阶邻居来补充从而得到更好的用户representation。然而,我们发现在训练数据上学习
《λOpt: Learn to Regularize Recommender Models in Finer Levels》的启发,它在验证数据上学习超参数。我们发现性能性能略有提升(小于1%)。我们将探索
item来进行个性化)作为未来的工作。
1.2 实验
我们首先描述实验设置,然后和
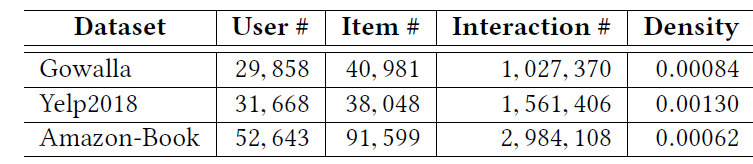
NGCF进行详细比较。NGCF是和LightGCN最相关、但是更复杂的方法。接下来我们将LightGCN和其它SOTA方法进行比较。为了证明LightGCN中的设计合理性并揭示其有效的原因,我们进行了消融研究和embedding分析。最后我们研究了超参数。数据集:为了减少实验工作量并保持公平的比较,我们密切遵循
NGCF工作的配置。我们从NGCF作者那里获取了实验数据集(包括训练集、测试集的拆分),其统计数据如下表所示。Gowalla和Amazon-Book和NGCF论文中使用的完全一致,因此我们直接使用NGCF论文中的结果。唯一的例外是
Yelp 2018数据集,这是一个修订版本。根据NGCF作者的说法,之前的版本没有过滤掉测试集中的冷启动item,他们只向我们分享了修订版本。因此,我们在Yelp 2018数据集上重新运行了NGCF。评估指标是由
all-ranking协议(用户的所有未交互的item都是候选item)计算的recall@20和ndcg@20。
对比方法:主要的对比方法是
NGCF,其表现优于多种方法,包括基于GCN的模型GC-MC, PinSage、基于神经网络的模型NeuMF, CMN、以及基于分解的模型MF, Hop-Rec。由于比较是在相同评估协议下的相同数据集上进行的,因此我们没有进一步和这些方法进行比较(仅仅比较了NGCF)。我们还进一步比较了两种相关的、且具有竞争力的
CF方法:Mult-VAE:这是一种基于变分自编码器(variational autoencoder: VAE)的、基于item的CF方法。它假设数据是从多项式分布中生成的,并使用变分推断(variational inference)进行参数估计。我们运行作者发布的代码,并在
[0, 0.2, 0.5]中调优dropout rate、在[0.2, 0.4, 0.6, 0.8]中调优600 -> 200 -> 600。GRMF:该方法通过添加图拉普拉斯正则化器(graph Laplacian regularizer)来平滑矩阵分解。为了公平地比较item推荐,我们将评分预测损失调整为BPR loss。GRMF的目标函数为:其中
LightGCN相同。此外,我们还比较了一个给拉普拉斯图增加归一化的变体:
这被称作
GRMF-norm。这两种GRMF方法通过拉普拉斯正则化器在训练中引入embedding平滑(测试时还是原始的embedding而没有平滑),而我们的LightGCN在预测模型中实现了embedding平滑。
超参数配置:
与
NGCF相同,所有模型的embedding大小固定为64,embedding参数使用Xavier方法初始化。我们使用
Adam优化器优化LightGCN,并使用默认的学习率0.001和默认的batch size = 1024(在Amazon-Book上,我们将batch size增加到2048以提高训练速度)。层组合系数
我们在
1 ~ 4的范围内测试早停和验证策略与
NGCF相同。通常,1000个epoch足以让LightGCN收敛。
我们的实现在
TensorFlow和PyTorch中都可用。
1.2.1 模型比较
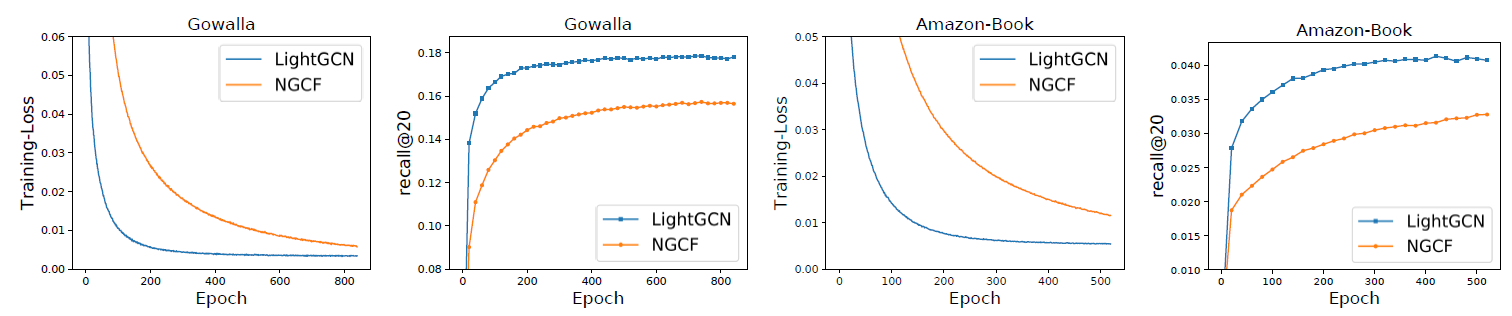
与
NGCF比较:我们与NGCF进行了详细的比较,下表中记录了不同层(1层到4层)的性能,还显示了每个指标的相对提升比例。其中NGCF在Gowalla和Amazon-Book上的结果来自于NGCF原始论文。我们在下图中进一步绘制了
training loss和testing recall的训练曲线(training curves),从而揭示LightGCN的优势,并明确训练过程。训练曲线是每隔20个epoch收集一次训练损失和测试召回率。Yelp2018结果的趋势和Gowalla/Amazon-Book相同,因为篇幅有限这里忽略Yelp2018的结果曲线。可以看到:
在所有情况下,
LightGCN的表现都远远超过NGCF。例如在
Gowalla数据集上,NGCF论文中报告的最高召回率为0.1570,而我们的LightGCN在4层设置下可以达到0.1830%,高出16.56%。平均而言,三个数据集的召回率提高了
16.52%、ndcg提高了16.87%,这是相当显著的提升。可以看到
LightGCN的性能优于NGCF-fn。NGCF-fn是删除特征变换和非线性激活的NGCF变体。由于NGCF-fn仍然包含比LightGCN更多的操作(如,自连接、图卷积中user embedding和item embedding之间的交互、dropout),这表明这些操作对于NGCF-fn也可能是无用的。增加层数可以提高性能,但是增益会逐渐减少。一般的观察是:将层数从
0(即矩阵分解模型)增加到1会导致最大的性能增益,并且在大多数情况下使用3层会导致令人满意的性能。这一观察结果和NGCF的发现一致。在训练过程中,
LightGCN始终获得较低的训练损失,这表明LightGCN比NGCF更容易拟合训练数据。此外,较低的训练损失成功地转化为更好的测试准确性(accuracy),这表明了LightGCN强大的泛化能力。相比之下,
NGCF较高的训练损失和较低的测试准确性反映了训练好如此重型heavy的模型的实际难度。
注意,在图中我们显示了两种方法在最佳超参数设置下的训练过程。虽然提高
NGCF的学习率可以降低其训练损失(甚至低于LightGCN),但是无法提高测试召回率,因为以这种方式降低训练损失只能为NGCF找到无效解 (trivial solution)。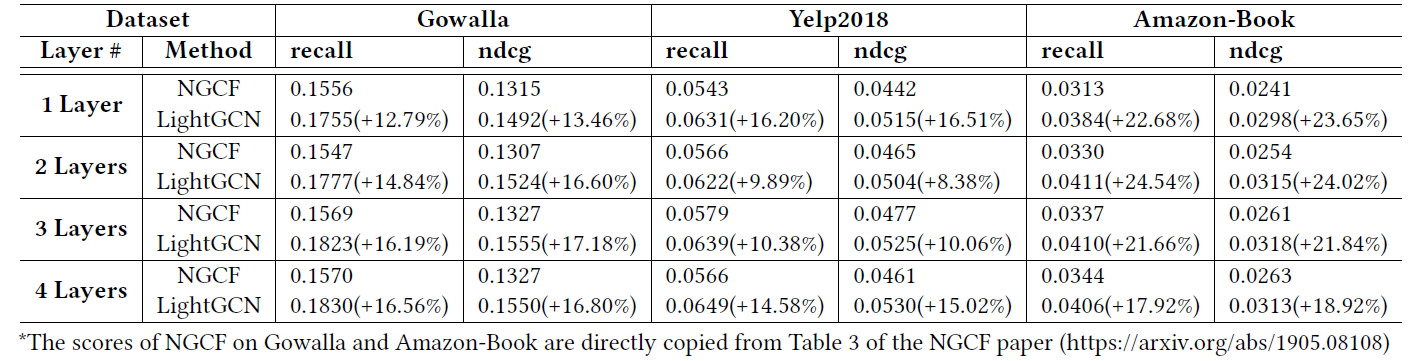
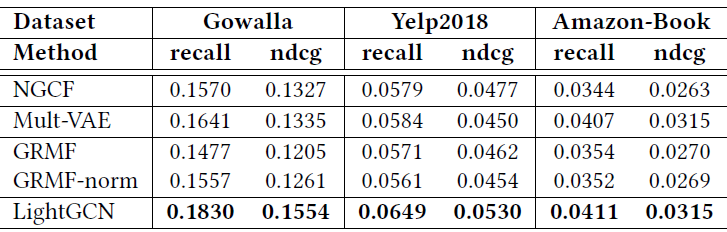
和
SOA模型的比较:下表给出了LightGCN和其它baseline方法的性能比较。我们展示了我们可以为每种方法获得的最佳得分。可以看到:
LightGCN在所有三个数据集上始终优于其它方法,证明了其简单而合理的设计的有效性。注意:
LightGCN可以通过调整over-tuning)。在所有
baseline中:Mult-VAE表现出最强的性能,优于GRMF和NGCF。GRMF的性能与NGCF相当,优于MF,这表明使用拉普拉斯正则化器强制embedding平滑的效果。通过在拉普拉斯正则化器中加入归一化,
GRMF-norm在Gowalla上优于GRMF、在Yelp2018和Amazon-Book上没有任何收益。
1.2.2 消融研究
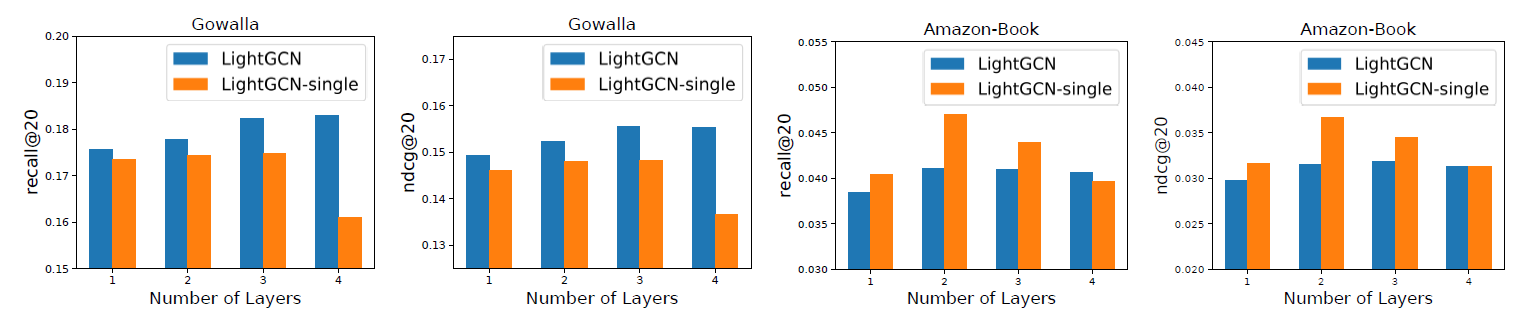
我们通过展示层组合(
layer combination)和对称的sqrt归一化如何影响LightGCN的性能来进行消融研究。为了证明前面分析的
LightGCN的合理性,我们进一步研究了embedding smoothness(这是LightGCN有效的关键原因)的影响。层组合的影响:下图显示了
LightGCN及其变体LightGCN-single的结果。其中LightGCN-single不使用层组合,即仅仅将LightGCN的最终预测。由于篇幅有限,我们省略了
Yelp2018上的结果,这与Amazon-Book显示出类似的趋势。可以看到:聚焦
LightGCN-single,我们发现:当层数从1增加到4时,它的性能先提升然后下降;在大多数情况下,峰值点在2层,然后迅速下降到4层这个最差点。这一结果表明:使用一阶和二阶邻居来平滑节点的
embedding对于CF非常有用,而在使用高阶邻居时会遇到过度平滑的问题。聚焦
LightGCN,我们发现:它的性能随着层数的增加而逐渐提高。即使使用4层,LightGCN的性能也不会下降。这证明了
layer combination解决过度平滑的有效性,正如我们前面技术分析中(和APPNP的关联)所表述的那样。比较这两种方法,我们发现:
LightGCN在Gowalla上的表现始终优于LightGCN-single,但是在Amazon-Book和Yelp2018上则不然(其中2层LightGCN-single表现最好)。对于这种现象,在得出结论之前需要注意两点:
LightGCN-single是LightGCN的特例。如果将LightGCN降级为LightGCN-single。在
LightGCN中,我们没有调优LightGCN性能的潜力。
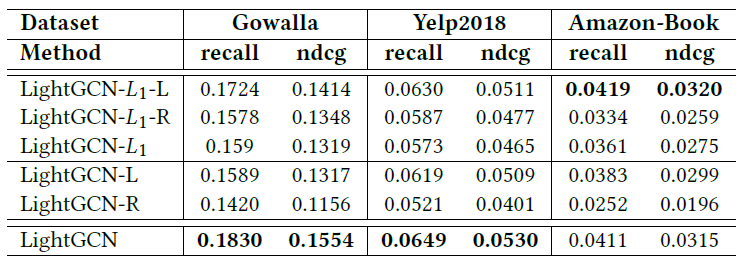
对称
sqrt归一化:在LightGCN中,我们在执行邻域聚合时对每个邻域embedding采用对称sqrt归一化仅使用左侧目标节点的系数,即左侧归一化,用
-L来表示。仅使用右侧邻居节点的系数,即右侧归一化,用
-R来表示。使用
L1归一化,即移除平方根,用-L1来表示。
注意,如果移除整个归一化本身,那么训练会变得数值不稳定,并且会受到
not-a-value:NAN问题的影响,因此这里我们不会比较这个配置。下表给出了
3层LightGCN的结果, 可以看到:一般而言,最佳设置是使用对称
sqrt归一化(即LightGCN的当前设计)。移除任何一侧都会大大降低性能。次优设置是仅在左侧使用
L1归一化,即LightGCN-L1-L,这相当于通过in degree将邻接矩阵归一化为随机矩阵(stochastic matrix)。两侧对称归一化有助于
sqrt归一化(即LightGCN vs LightGCN-L/LightGCN-R),但是会降低L1归一化的性能(即LightGCN-L1 vs LightGCN-L1-L/LightGCN-L1-R)。
Embedding Smoothness分析:正如我们在前面分析的那样,一个2层LightGCN根据用户交互item上重叠(overlap)的用户来平滑用户的embedding,两个用户之间的平滑强度(smoothing strength)我们推测这种
embedding平滑是LightGCN有效性的关键原因。为了验证这一点,我们首先将用户embedding的平滑性定义为:其中
embedding的L2范数用于消除embedding幅度(scale)的影响。类似地,我们可以获得
item embedding的平滑性定义。理论上如果两个用户平滑强度
smoothness loss),该值越小那么embedding越平滑。下表显式了矩阵分解(即使用
2层的LightGCN-single(即使用2层LightGCN-single在推荐准确性方面远远超过MF。可以看到:
LightGCN-single的平滑性损失远远低于MF。这表明,通过进行light graph convolution,embedding变得更平滑、更适合用于推荐。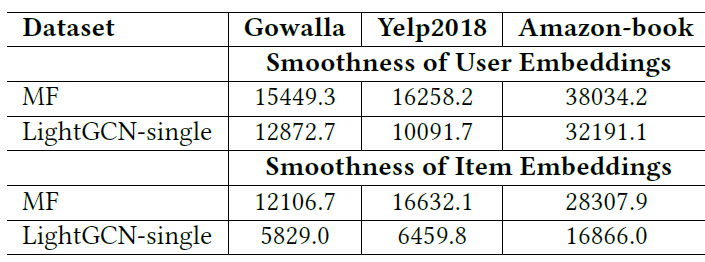
1.2.3 超参数研究
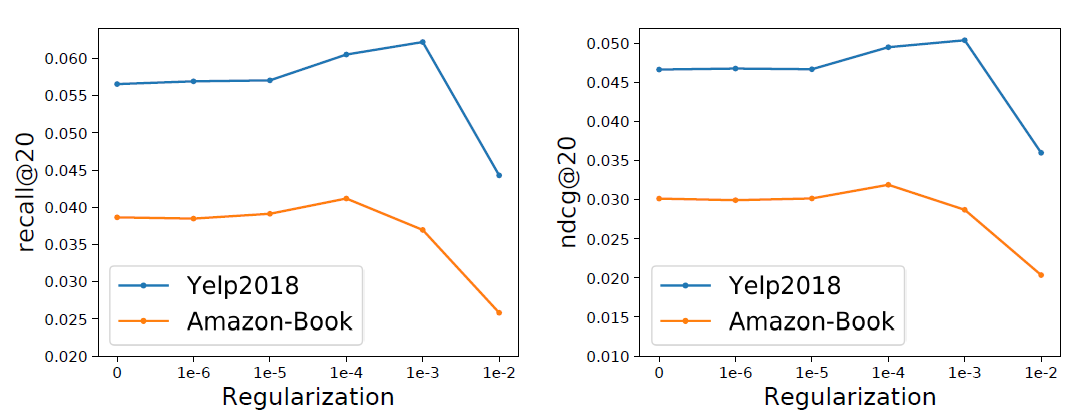
当
LightGCN应用于新数据集时,除了标准的超参数学习率之外,最重要的超参数是L2正则化系数2层的LightGCN的性能针对超参数LightGCN对LightGCN也比NGCF要好。而NGCF额外使用dropout来防止过拟合。这表明
LightGCN不太容易过拟合,因为LightGCN中唯一可训练的参数是第0层的ID embedding,所以模型很容易训练和正则化。Yelp 2018、Amazon-Book、Gowalla数据集上,当
我们相信
LightGCN的洞察对推荐模型的未来发展具有启发意义。随着链接图数据linked graph data在实际应用中的流行,基于图的模型在推荐中变得越来越重要。通过显式地利用预测模型中实体之间的关系,基于图的模型优于传统的监督学习方案(如隐式利用实体之间关系的分解机FM)。例如,最近的一个趋势是利用辅助信息,如
item知识图、社交网络、多媒体内容,从而进行推荐。在这个过程中,GCN已经建立了SOTA技术。然而,这些模型也可能会遇到NGCF的类似问题,因为user-item交互图也由相同的、可能不必要的神经操作建模。我们未来计划在这些模型中探索LightGCN的思想。另一个未来的方向是个性化层组合权重
最后,我们将进一步探索
LightGCN简单性的优势,研究非采样回归损失(non-sampling regression loss)是否存在快速解决方案,并将其流式传输streaming到在线工业场景。